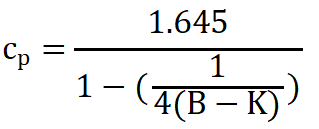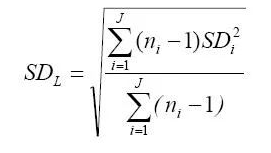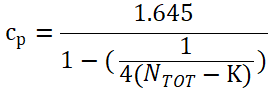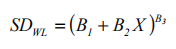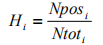|
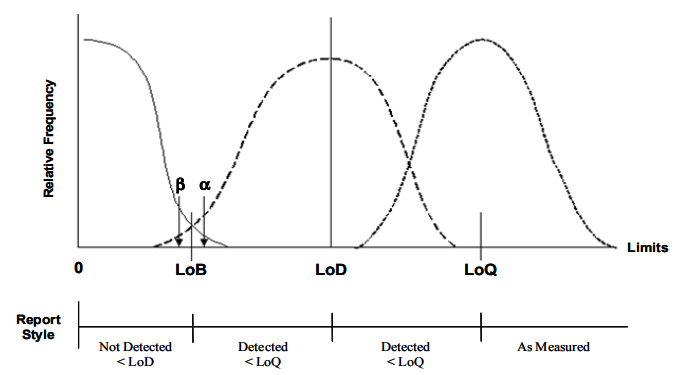
分析灵敏度是大多数体外诊断产品(IVD)非常重要指标之一,通常包含空白限(limit of blank,LoB),检测限(limit of detection,LoD),定量限(Limit of quantitation,LoQ)。这个指标也是IVD在进行欧盟IVDR认证、FDA 510K等申报中需要考虑的。进行分析灵敏度的性能研究目前相对比较详细及认可参考标准之一是CLSI EP17。 空白限,检测限,定量限具体怎么理解?制造商如何开展LoB, LoD, LoQ的研究?相信这是大家比较关心的问题,接下来国瑞中安集团-IVDEAR团队将通过以下内容给大家进行逐一介绍。 Section I - 空白限,检测限及定量限的理解 Section II - 企业如何建立空白限,检测限及定量限 · Part I LoB的建立实验之Classical法 · Part II LoD的建立 1.建立LoD的三种实验方法介绍 2.建立LoD之Classical 法 3.建立LoD之Precision profile 法 4.建立LoD之Probit概率法 · Part III LoQ的建立 定量检测的体外诊断产品对样本浓度下限检出能力指标包括:空白限(LoB)、检出限(LoD)及定量限(LoQ)。 首先了解一下三者各自的意义: LoB:limit of blank, 空白限,空白样本(样本浓度接近为0),可观察到的最高测量结果(对零浓度样本不能检出的能力,是指绝大部分(95%)零浓度样本测试的结果为阴性,不能出现假阳性,也就是我们熟知的第一类错误(α错误)。 LoD:limit of detection, 最低检测限, 在定量和定性分子测量程序中,能够一致检测到的分析物的最低浓度。(是指对有浓度的样本检出的能力,是指绝大部分(95%)的低浓度或极限浓度样本的测试结果为阳性,不能出现假阴性,也就是第二类错误(β错误))。 LoQ:Limit of quantitation定量限,LoQ是指对已知具体浓度值样本的稳定且准确测试能力。 根据上面概念,我们可以简单理解成: · LOB是不含有待测物时可能检测的最大浓度; · LOD是大于LOB的可被检出的实际浓度; · LOQ是能够被可靠检出的最低实际浓度。
一般情况下,三者的浓度大小关系如下图:
首先介绍三者之间的建立顺序关系:LoB,LoD及LoQ是对检测程序的多重检测能力估计,在低端区域内逐步的增加的定量确定性,以充分表征在测量区间的低端区域的性能。它们的建立顺序:LoB → LoD → LoQ。 LoB的建立的实验设计是采用经典法,它使用在一组空白样本进行的测量,并根据测量结果数据的统计分布情况,取两种方法中的一种去计算LoB值。 在进行任何实验之前,都应该先确定基本的试验设计,样本要求,数据分析的方案。因此本节介绍了LoB 的建立实验方案中的这三个基本要素。 1. 最小实验设计 最小实验设计考虑的设计因素有批号,测试设备,测试天数,样本数,重复测试次数这5个因素,以及规定了这5个因素的最小水平数。此外,根据特定的测量程序和所需的结果估计的统计严谨性,可能适当增加实验设计中的设计因素、某些因素的水平数和/或需要获得的重复测量的数量。最小实验设计要求:每天在同一个系统上,至少两批试剂,选择4个空白样本,每个样本重复测试两次,测试三天的设计,因此最小设计将会产生每个试剂批次共有60个测试结果。 2. 样本选择 在最小实验设计中提到,至少需要空白样本4个及以上。 3. 数据分析 在进行LoB的建立实验结果的数据分析之前,需要先观察数据结果的整体分布情况,从而选择不同的计算方法得出LoB。数据结果分为两种情况,正态和非正态分布。数据呈现如下图所示的是正态分布,其他的则归为非正态分布。
3.1 非正态分布下LoB 的计算 记录即步骤(3)中样本位置的测量结果值为LoB。如果位置为非整数,LoB的计算参考以下例子: a. 将所有B个空白样本的测试结果从小到大进行排列。 b. 根据期望的I型错误α的大小,确定最后用于计算的百分比,比如α=0.05,则百分比为95%。 c. 根据上述百分比,计算从小到大排列的空白样本的第95%个样本的位置,计算公式为:0.5+B×0.95,假如计算结果不是整数,则按照以下方式进行计算。 如B=60,则0.5+60×0.95=57.5,则LoB的浓度位于第57个测试值和58个测试值中间,LoB=X57+0.5×(X58-X57)。 3.2 正态分布下LoB 的计算 当低值样本结果数据为正态分布,LoB可以采用以下公式进行计算: Step 1: 计算所有空白样本测试值的平均值MB和标准差SDB; Step 2: LoB=MB+ cpSDB
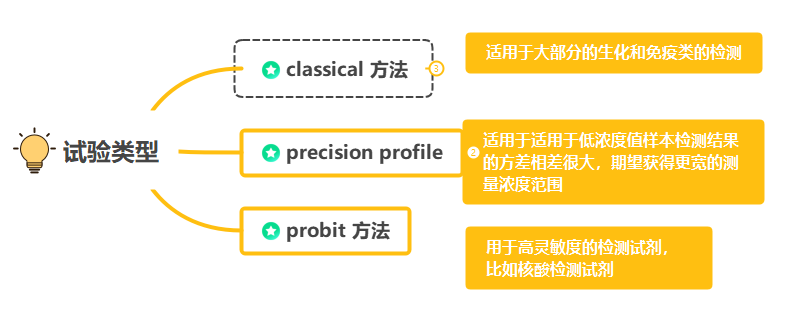
其中:Cp是乘数,表示正态分布的第95百分位(α=0.05),B实际测试过程中空白样本的个数,K为空白样本的个数。 LoD 的建立有三种方法,本节先介绍三种实验方法适用情况,然后依次介绍三种方法的基本试验设计,样本要求,数据分析的方案,重点分析三种方法中的数据分析计算公式。 1. 建立LoD的三种实验方法介绍 LoD建立的三种方法:经典法,精密度范围法,Probit 概率法,适用情况如下:
2. 建立LoD之Classical 法 2.1. 最小实验设计 每天在同一个系统上,至少两批试剂,选择4个低测量含量(阳性)样品,每个样本重复测试两次,测试三天的设计,因此最小设计将会产生每个试剂批次共有60个测试结果。 2.2. 样本选择 在最小实验设计中提到,至少需要低浓度样本4个及以上。 2.3. 数据分析 Step 1计算每个低水平样本集的SDL,公式如下:
Step 2 计算LoD:LoD=LoB+ cpSDL 其中SDi为第i个低值样本的标准差,ni为第i个低值样本的检测数,J为低值样本个数,Cp的意义的前面一个公式相同。 3. 建立LoD之Precision Profile 法 3.1. 最小实验设计 每天在同一个系统上,至少两批试剂,选择5个阳性样品,每个样本重复测试5次,测试5天的设计。 注意:前四个点,如果我每个样本测5次,到第5天,总共测了25个重复 ,那其实还是不满足最后一点要求,所以要增加测试天数,或者每天的重复量。 3.2 样本选择 在最小实验设计中提到,至少需要低浓度样本5个及以上。 3.3 数据分析 先计算出偏差SD值, 然后LoD=LoB+ cpSDL 。 其中NTOT是测量结果总数,用于构建精密度剖面的所有K项精密度研究的结果。
其中SD的计算有两种模型,取决于测试样本浓度水平的范围。足够窄的测试范围,可用线性模型linear model。
其他模型:Sadler precision profile model。
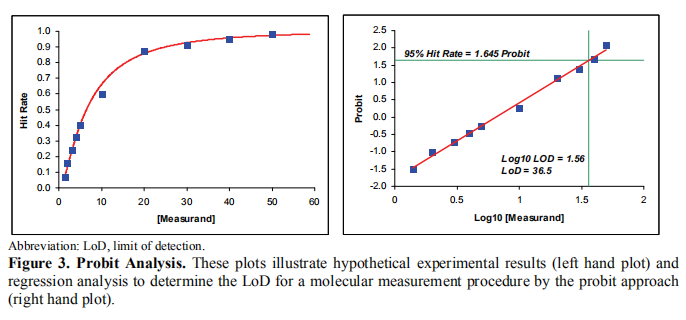
4. 建立LoD之Probit概率法 4.1最小实验设计 每天在同一个系统上,至少两批试剂,选择3个已知测量值的阳性样品(每个阳性样本的至少5个稀释度),每个阳性稀释样本重复测试20次,30 个阴性样本,每个阴性样本重复2次的设计。 4.2 样本选择 在最小实验设计中提到,至少需要3个已知的浓度的阳性样本(本个样本稀释成至少5个梯度浓度),30个阴性样本(真实样本,也可以做成样本pools)。 此处样本的选择,需要考虑以下这些情况: a. 考虑基因型的情况,分别要至少3个样本(或者与监管机构沟通); b. 不太常见或临床相关性较低的基因型可以通过验证试验(见7.3节)获得; c. 因此,需要用一样本进行初步测试来判断稀释比例和要稀释的次数; d. 方法是将稀释作为目标假设LoD水平的几何级数。假定稀释剂系列浓度在可接受的线性测量浓度范围内和确有该浓度的患者。增加稀释次数超过5个(最小要求)可能有助于提高模型的质量。 4.3数据分析 Step 1 用以下公式,计算每个样本的每个浓度测试结果的命中率hit rate,Hi ;
Step 2 使用电脑软件进行probit 分析,Y轴为命中率,X 轴为浓度(或log10(浓度)),进行概率拟合; Step 3 根据相应的预期β错误(β=0.05),得到可接受的命中率hit rate=0.95,在probit图中得hit rate=0.95对应的浓度值,即LoD。 注意:在分析测试结果的时候注意,要想得到一个较好的拟合效果(如下图所示),每个样本的稀释系列应使至少三次稀释样本的命中率hit rate在0.10-0.90和至少一次稀释样本hit rate大于0.95。有一个以上是不可取的任意极端稀释(即< 0.10和/或> 0.95),因为这可能会影响probit的质量模型拟合和结果LoD估计。
Part II,我们介绍了LoD 的建立的三种方法的基本试验设计,样本要求,数据分析的方案,重点分析三种方法中的数据分析计算公式。本节继续分享LoQ建立实验的基本试验设计,样本要求,数据分析的方案。 首先我们回顾一下LoQ的概念,是指在一定试验条件下,达到预设准确度要求时可测量的最低待测物浓度。LoQ的大小和测量的程序以及预设的准确度要求有关。要求越严格,LoQ值越大。 本篇内容介绍了LoQ的建立实验方案中的基本试验设计,样本要求,数据分析的方法: 1. 最小实验设计 每天在同一个系统上,至少两批试剂,选择4个独立的已知测量值的低水平样品,每个样本重复测试3次,测试3天的设计。因此,每批试剂将产生36个测量结果。 2. 样本选择 至少需要4个独立低水平样本(已知浓度水平),每个试剂批次总低水平样品重复36次(包括所有低水平样品、仪器系统和天数) 注:LoD的实验设计的样品采用不同的浓度,而LoQ是单一目标浓度。 3. 数据分析 前面提到,LoQ 是满足预设准确度要求时可测量的最低待测物浓度。在EP17-A2指南中提到的预设准确度的衡量有“总误差值(TE)”或者为“偏差值(Bias)”加“精密度值(precision)”这几种指标 以总误差这个指标来衡量准确度,从而计算LoQ为例,计算步骤如下: Step 1:计算每个低值样本所有重复次数结果的平均值x,SDs Step 2: 计算每个低值样本与赋值R的偏差bias, Bias = Step 3: 使用Westgard model /RMS model计算总误差TE Step 4: 比较TE和预期定义的精确度目标,若符合要求则取最低浓度为该批次LoQ。 本篇分享如何理解LoB, LoD, LoQ,以及企业应该如何建立三者值的具体实验设计,样本选择和数据分析方法。这些指标的评估是技术资料的重要内容,希望通过这一篇干货分享,对大家之后进行欧盟IVDR认证、FDA 510K等进行报告的编写有所帮助。 |
Copyright © 2015-2026 杭州宇翼科技有限公司 丨 Discuz! X3.5 丨增值电信业务经营许可证:浙B2-20190572丨浙ICP备18026348号-1丨浙公网安备33010802009352号