|
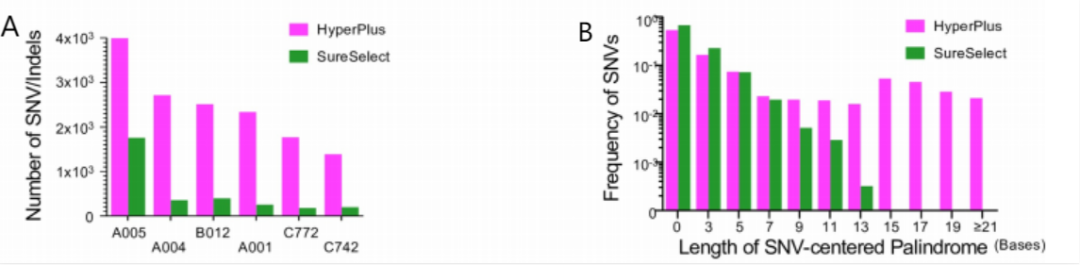
癌症是威胁人类健康的严重疾病之一。近年来,我国癌症发病仍处于逐年上升的态势,为肿瘤检测提出了更高的要求。高通量测序为肿瘤检测提供了一种全新的方法,相较于传统的影像学检查、肿瘤标记物检测和组织活检,肿瘤NGS检测具备高灵敏性,多基因平行检测等优点,还可以检测罕见突变位点,为癌症、遗传病等复杂疾病诊疗带来新的契机。但肿瘤NGS检测的高深度测序也带来了大量的假阳性,给NGS结果的判读带来了一定的难度。 通常高通量测序过程包括样本的储存和处理、核酸提取、片段化、文库扩增、测序和生物信息学分析。在文库构建过程中,片段化过程中发生的错误,会进一步导致扩增偏差,进而影响文库扩增后的准确性,并产生背景噪音。因此,减少片段化过程中产生的偏差尤为重要。 酶法 根据Chigusa S等人的研究[1],相对于机械打断法,酶法构建的文库中的Artifact SNV/Indel的数量要大得多。如图2A所示,使用片段化酶法构建文库的SNV/Indel检测数是使用机械法构建的文库的2.3~9.9倍。此外,许多体细胞SNV恰好位于回文序列的中心,称为SNV-centered palindromes(SCPs),使用片段化酶法构建的文库中含有更多且长度更长的SCP,如图2B所示。
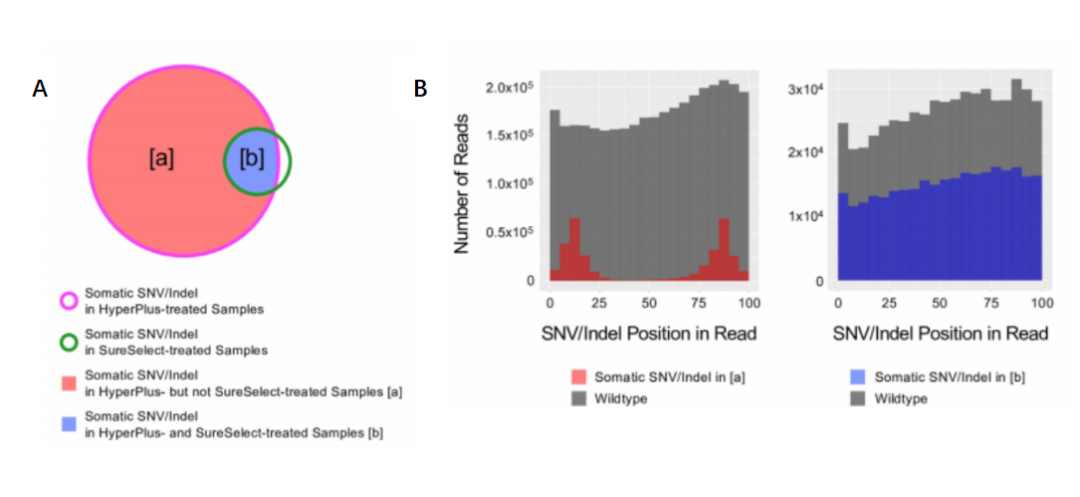
对使用片段化酶法和机械法构建文库中的SNV/Indel进行分类,可以发现使用不同建库方法构建文库的SNV/Indel检出有相交的部分(图3A)。我们可以将这个部分理解为真实存在的SNV/Indel。此外,片段化酶法构建的文库中出现了大量在机械法构建文库中没有出现的部分,这个部分就是假阳性突变。 如图3B所示,使用片段化酶法构建的文库中,SNV/Indel通常位于3‘或5’末端10-15个碱基的位置。而使用机械法构建的文库中,SNV/Indel分布比较均匀。
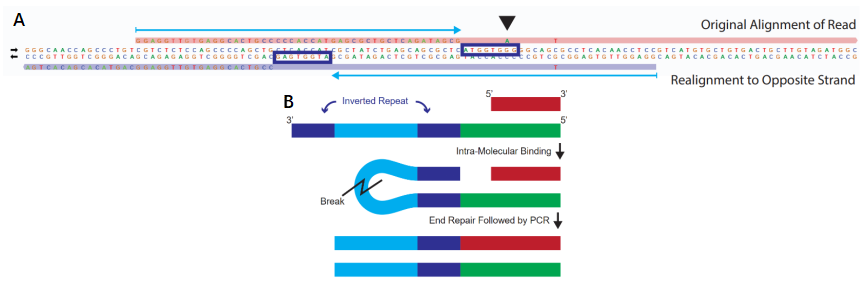
在片段化酶法构建的文库中,这些假阳性突变是如何产生的呢? 在分析片段化酶法打断的文库时,经常会发现一些人工合成的序列(Artifact reads)。通常这些Artifact reads碱基质量高,表示它们是真实分子的衍生物,而不是测序过程中产生的错误,并且这些Artifact reads通常能在附近的参考序列中找到反向互补序列(如图4A所示)。这种高碱基质量的Artifact reads可能会导致SNV/Indel的误报,出现假阳性突变。 根据Gregory T等人的研究[2],在酶的作用下,DNA分子暴露了某些反向互补序列,这样的反向互补序列异常结合在一起,就会导致DNA序列发生结构上的改变(颈环结构)(如图4B所示),形成假阳性突变。
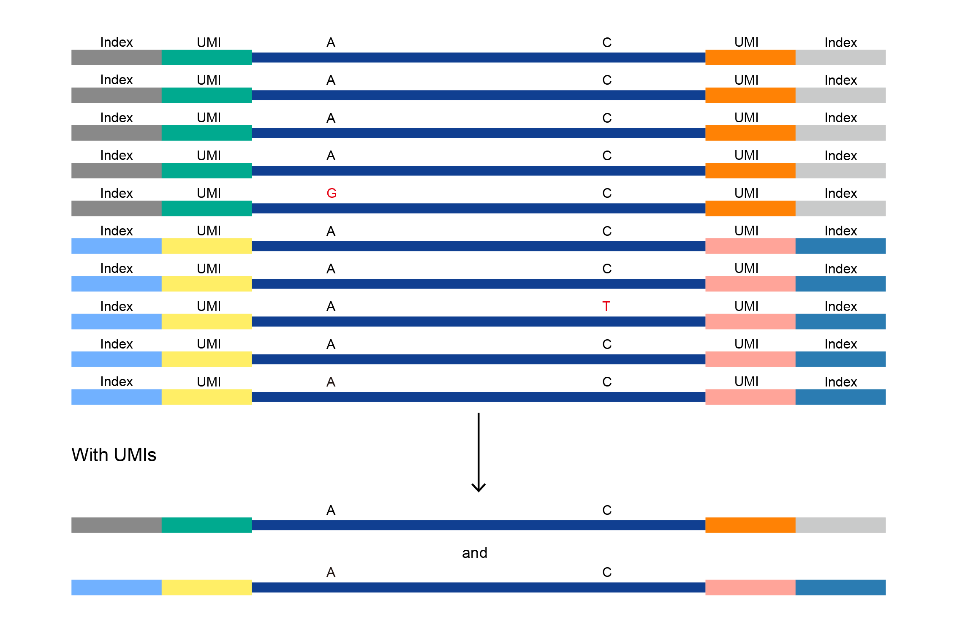
文库扩增和测序过程 那么在文库扩增以及测序过程中,是否会造成假阳性突变呢?答案是肯定的。 为解决片段化和文库扩增、测序过程中产生假阳性突变问题,可以在接头连接过程中,使用含有UMI标签的接头。 UMI (Unique Molecular Identifiers)通常设计为完全随机的核苷酸链(如NNNNNN)、部分简并核苷酸链(如NNNRNYN)或者固定核苷酸链(当模板分子有限的情况下)。从图5可以看出,片段化和末端修复后的同一个DNA分子在测序后会产生多条reads,其中有个别碱基出现了突变(标红的碱基),这就是文库扩增和测序过长中产生的假阳性突变。引入UMI标签,剔除扩增和测序过程中产生的假阳性突变,可以提高低频突变检出率。
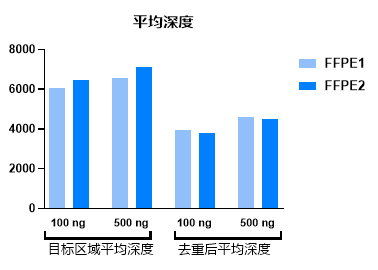
为解决片段化酶法建库产生假阳性突变的问题,诺唯赞研发团队针对性的进行了体系优化和升级,从源头上降低片段化酶法建库中的假阳性突变。诺唯赞即将推出升级版片段化酶法建库试剂盒VAHTS®Universal Plus DNA Library Prep Kit for Illumina V2(Vazyme #ND627),搭配双端UDI UMI接头VAHTS®Dual UMI UDI Adapters Set 1- Set 4 for Illumina(Vazyme #N351-N354),可降低假阳性突变,使检测结果准确性更高,更加可信。 以下为Vazyme #ND627首批客户测试反馈: 使用两个不同的FFPE样本进行测试,样本输入量为100 ng、500 ng,捕获后上机测序。下机数据量约8000 M,目标区域去重后的平均深度仍能达到4000 ×以上,可以达到生信分析的要求。
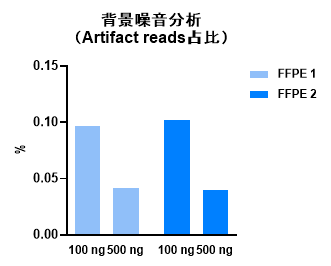
图6. 下机数据平均深度。 对所测样本的Artifact reads占比进行分析,使用Vazyme #ND627进行文库构建后,Artifact reads占比可低至0.1%,极大降低了SNV/Indel检出假阳性。
本文编辑:乐乐高 |
Copyright © 2015-2026 杭州宇翼科技有限公司 丨 Discuz! X3.5 丨增值电信业务经营许可证:浙B2-20190572丨浙ICP备18026348号-1丨浙公网安备33010802009352号