|
———— / BEGIN / ————
在医学诊断中,全血细胞计数是一项评估整体健康状况的重要检测。传统上,血细胞是用血细胞计数器及其他实验室设备和化学染料来人工识别计数的,是一种既耗时又枯燥乏味的工作。本文介绍了一种“你只用看一遍”(YOLO)目标检测和分类算法对三种类型血细胞进行自动识别和计数的机器学习方法。
用修改配置后的血涂片图像BCCD数据集来训练YOLO框架,以自动识别和计算红细胞、白细胞和血小板的数量。此外,考虑到架构复杂性、报告准确性和框架运行时间,本研究还对其他卷积神经网络架构进行了实验,并比较了不同模型检测血细胞的准确度。
还用另一个不同数据集的血涂片图像测试了训练模型,结果发现学习后的模型具有普遍适用性。总之,计算机辅助检测和计数系统使我们能够在不到一秒钟内计算出血涂片图像中的血细胞数,这对于实际应用意义重大。 全血细胞计数(CBC)是医护人员常用于评估健康状况的一项重要检测。构成血液的三种主要细胞是红细胞(RBCs)、白细胞(WBCs)和血小板。
RBCs也称为红血球,是血液中数量最多的一种血细胞,约占40%-45%[美国血液学协会:http://www.hematology.org/Patients/Basics/]。
血小板也称为凝血细胞,在血液中数量也很多。WBC又称为白血球,仅占血细胞总数的1%。RBCs将氧气运送到我们的身体组织,组织接收的含氧量受RBCs数量影响。
WBC能抵抗感染,而血小板有助于凝血。由于这些血细胞的数量巨大,传统上使用血细胞计数器的手动血细胞计数系统极其费时且容易出错,在大多数情况下,计数的准确度高度取决于临床实验室技师的技能。
因此,血涂片图像中多种血细胞的自动计数过程将大大地促进整个计数过程。
随着机器学习技术的发展,图像分类和目标检测应用越来越稳健,也越来越准确。因此,基于机器学习的方法被应用到各个领域。
尤其是,深度学习方法被应用到多个医学领域,如胸部X光片的异常检测和定位,心脏MRI图像的左心室自动分割,以及视网膜眼底照片中糖尿病视网膜病变的检测。
因而,值得探讨可用于识别和计算血涂片图像中血细胞数的深度学习方法。
本文介绍了一种基于深度学习的血细胞计数方法。我们利用基于深度学习的目标检测方法鉴别不同类型的血细胞。在卷积神经网络(R-CNN)、你只用看一遍(YOLO)等最先进的目标检测算法中,我们选择了YOLO框架,它比采用VGG-16架构的Faster R-CNN约快三倍。
YOLO使用单个神经网络直接根据完整图像一次性预测边界框(bounding box)和类别概率。我们再次训练YOLO框架,以自动识别和计算血涂片图像中的RBCs、WBCs和血小板数。
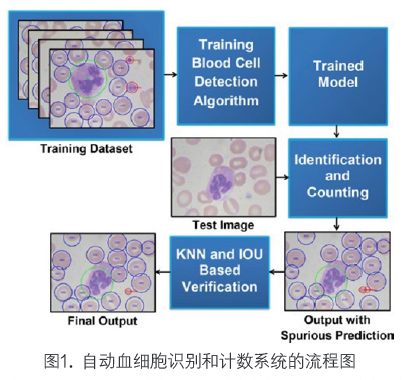
为了提高计数准确度,我们还开发了一种验证方法来避免框架重复计数。另外,我们用另一个数据集的图像测试了训练模型,以明确方法的普遍适用性。图1是我们提出的基于深度学习的血细胞识别和计数系统。
一般来说,有两种方法可用于血细胞的自动计数过程。这两种方法分别是图像处理法和机器学习法。Acharya和Kumar提出了用于RBCs计数的图像处理法。这种方法通过处理血涂片图像进行RBC计数,并识别正常和异常细胞。
他们使用K-medoids算法从图像中提取WBC,然后通过粒度分析将RBC与WBC分离,再使用标记算法和圆霍夫变换(CHT)对RBC进行计数。Sarrafzadeh等人提出用圆环变换对灰度图像中的RBC进行计数,使用迭代软阈值法进行识别和计数。
Kaur等人提出了一种通过CHT自动计算显微血细胞图像中血小板数的方法,根据CHT的血小板大小和形状特征进行计数。Cruz等人介绍了一种用于血细胞计数的图像处理法,用色相、饱和度、值阈值方法和连接成分标记进行血细胞识别和计数。
Acharjee等人提出通过霍夫变换检测椭圆形和双凹形状进行RBC计数的半自动方法。Lou等人提出利用光谱角度成像和支持向量机(SVM)自动计算RBC数的方法。
Zhao等人提出了基于卷积神经网络(CNN)的WBC自动识别和分类方法,首先找出显微图像中的WBC,然后用CNN识别各种WBC。Habibzadeh等人介绍了一种WBC五分类系统,在这个过程中使用了三个分类器,包括两个不同的SVM和一个CNN分类器。
Habibzadeh等人利用预先训练的CNN、ResNet和Inception Net计算分割图像中的WBC数,利用颜色空间分析对图像进行分割。Xu等人首先对预处理的图像进行补丁大小标准化,然后用CNN对镰状细胞病患者显微镜图像中的RBC形状进行分类。
不同于以上所有的方法,我们利用YOLO同时检测三种血细胞类型。我们的方法不需要任何灰度转换或二元分割。整个过程完全自动化、速度快且准确。 我们的目标是使用目标检测和分类算法YOLO直接对血涂片图像中的血细胞进行识别和计数。我们需要用修改后的配置和带注释的血细胞训练图像来训练YOLO框架。
1. 数据集:我们使用了一个公开的带注释的血细胞图像数据集,即血细胞计数据集(BCCD)[BCCD:https://github.com/Shenggan/BCCD_Dataset]。最初,该数据集共有364幅带注释的血涂片图像,但是它存在一些明显的缺陷。将此数据集分为训练集(300幅图像)和测试集(64幅图像)后,我们发现测试集中的一个注释文件不包含任何RBC,但是图像包含RBC。
此外,还有三个注释文件显示远远低于实际数量的RBC。因此,我们删除了这4个不合理的文件,最终测试集包含60幅图像。我们随机选择了60幅带注释的训练图像组成验证集。可从GitHub资源库下载修改后的数据集(https://github.com/MahmudulAlam/Complete-Blood-Cell-Count-Dataset)。
我们使用了另外的数据集测试训练模型。该数据集包括100幅分辨率为3246×2448的图像,这些图像是用Nikon ECLIPSE 50i显微镜上的Nikon V1相机拍摄的,放大倍数为100倍。
2. YOLO算法:“你只看一遍”,简称YOLO,是目前最先进的目标检测分类算法。它将目标检测视为回归问题。它只需要通过网络进行一次前向传播即可对图像类别和位置进行快速预测。
它将图像大小调整为448×448,并将整个图像划分为7×7的网格单元,每个网格单元预测两个边界框和对应边界框的置信度得分。如果目标的中心落在一个网格单元中,则该网格单元负责检测此目标。
最初实施的YOLO模型,是经过PASCAL VOC数据集评估的CNN。受到GoogLeNet的启发,它的网络架构包含24个卷积层和2个全连接层。在不同的YOLO版本中,我们选择使用Tiny YOLO,因为这个版本是最快的。除了用9个卷积层代替24个卷积层以外,Tiny YOLO在所有参数上保持不变。
3. 训练:最初的Tiny YOLO配置经过了20个不同类别的训练。为了使其适用于血细胞识别,我们将其改为包含WBC、RBC和血小板三个类别。由于改变了类别数,CNN架构中最终卷积层(final convolutional Layer)的过滤器数也需要变化。
YOLO会预测出每个锚框(anchor box)的5个值及类别概率。这5个值分别是目标落在网格单元的概率、目标的x和y坐标、目标的高度和宽度。在我们的方法中,锚框的数量为5,因为它将根据目标的高宽比更灵活地放置边界框。最终卷积层的过滤器数NF,可以根据锚框数NA和类别数NC计算出来:
NF =NA×(NC +5)(1)在实验中,NA是5,NC是3,因此NF为40。
我们使用300张带注释的血液涂片图像进行训练,60张用于测试。我们记录每一步训练中的损失值和移动平均损失值。我们共记录了4500个步骤的数据,并使用了两种不同的学习速率。
第1-2500步的学习速率是10-5,第2501-4500步的学习速率是10-7。结果发现,在第2501-4500步采用较低的学习速率可以实现更好的收敛(convergence)。我们每隔125步记录一次权重并评估模型。图2是用损失函数表示的YOLO血细胞检测算法的学习曲线。
图中同时给出了损失函数的损失值和移动平均损失值。从图中可以看出,在学习速率为10-7时第3750步的移动平均损失值最小,为8.8766。我们利用此步的权重进行测试。

4. YOLO血细胞识别和计数方法:我们提出用机器学习方法,即YOLO算法对血细胞进行自动识别和计数。这种方法包括配置经过修改的训练模型,我们将最终卷积层改为三种输出,根据适当的阈值识别血细胞并根据标记进行计数。
我们通过计算基础真值与在不同阈值所得的估计值之间的平均绝对误差来选择阈值,并找到每种细胞的适当阈值,即在该阈值下验证数据集中的平均绝对误差最小。我们提出的方法(即YOLO血细胞识别和计数方法)不会误判细胞类型,比如,不会将RBC误判为WBC或将血小板误判为RBC等。
在某些情况下,它会重复计算血小板的数量。我们通过对每个血小板应用K近邻算法(KNN)和交并比算法(IOU)来解决这一问题。总而言之,YOLO血细胞识别和计数方法既快速又准确。该方法的步骤如算法1(见图3)所述。

对于检测的每种细胞,YOLO模型会得出4个参数。这4个参数分别是该细胞的标记、该细胞的置信度、左上角位置和右下角位置。我们有两种方法可以显示在血涂片图像中检测到的细胞。
我们可以用左上角和右下角坐标,将检测到的每个细胞放到一个矩形边界框内。然而,血细胞并不是矩形的,在形状上更接近于圆形,而且矩形框所占的空间比所需空间大得多。
因此,我们用圆形边界框来标记每个细胞,这需要将左上角和右下角坐标转换为圆形的半径和中心点。
鉴于左上角和右下角坐标分别是(x1,y1)和(x2,y2),因此,用于标记细胞的圆形的中心点C和半径r可以计算为:
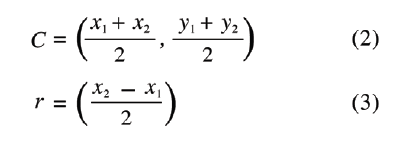
我们根据细胞的标记进行计数。根据检测的细胞类型,修改后的YOLO算法会返回三种标记,即“RBC”、“WBC”和“血小板”。一个涂片图像中的RBC总数就是包含“RBC”标记的总数,WBC总数就是包含“WBC”标记的总数,以此类推。
在某些情况下,同一血小板被计数两次,这是因为两个连续的网格单元检测到相同的血小板。为了避免这种重复计数现象,我们首先用KNN算法确定每个血小板的邻近血小板,然后用两个血小板之间的交并比(IOU)来计算重叠度。
依据经验,血小板与邻近血小板之间的允许重叠度是10%。如果重叠度大于10%,我们将忽略该细胞的重复计数,以排除虚假计数。图4表示血小板被YOLO算法计数两次的情况。利用KNN和IOU技术可以解决重复计数问题。 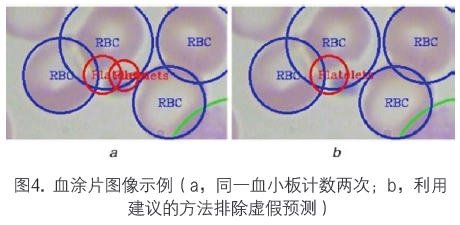
我们用YOLO方法对RBC、WBC和血小板进行自动识别和计数。并用60幅图像组成的测试数据集(已知基础真值)测试我们的YOLO模型。首先使用我们的模型来计数不同置信阈值的验证数据集中的不同细胞。
请注意,阈值在YOLO算法中发挥重要的作用,因为YOLO利用该阈值预测每个网格单元,而不是整个图像。不包含血细胞的网格单元置信度较低。因此,我们可以通过选择适当的置信阈值来避免多余的和虚假的预测。
我们计算了基础真值与验证数据集的估计细胞数之间的平均绝对误差。利用不同的置信阈值,使每种细胞的平均绝对误差值达到最低,并将这些置信值用于血细胞的识别过程。误差的计算公式如下:
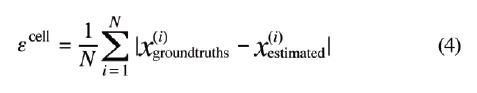
其中,cell代表细胞类型(RBC、WBC或PLT),N是验证数据集的大小(在我们的实验中,N=60),χ是细胞数,ε是特定细胞的平均绝对误差值。计算所得的误差值如表1所示。
从表中可以看出,RBC计数的阈值是0.55。而WBC和PLT的阈值则低得多(在我们的实验中分别是0.35和0.25)。因此,每种细胞的阈值被选定为: (1)RBC:置信阈值为55%; (2)WBC:置信阈值为35%; (3)PLT:置信阈值为25%。

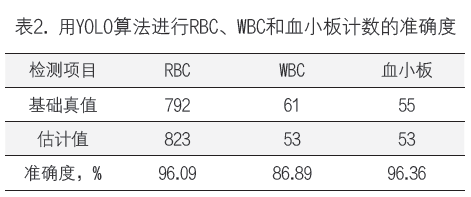
然后,我们根据基础真值细胞的总数和测试数据集的估计细胞总数计算准确度。在55%置信阈值,RBC计数的准确度达到了96.09%。不同类型细胞的估计总数和在适当置信阈值计算的准确度如表2所示。
YOLO算法给出的RBC计数似乎高于图像中的实际RBC计数。但是,我们必须指出,对于某些位于图像边缘的RBC,并未给出基础真值标记。YOLO算法能够检测到这些RBC,因此RBC计数较高。
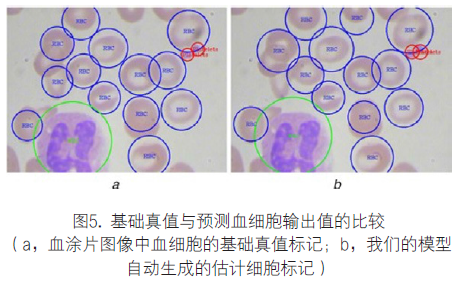
为了形象化地比较基础真值与YOLO方法的输出值,图5表示来自测试集的一个样品血涂片图像。从图中可以看出,所有WBC和PLT计数均无误。该方法漏掉了中间的一个RBC,但是检测到图像边缘的另一个RBC(不包括在基础真值中)。
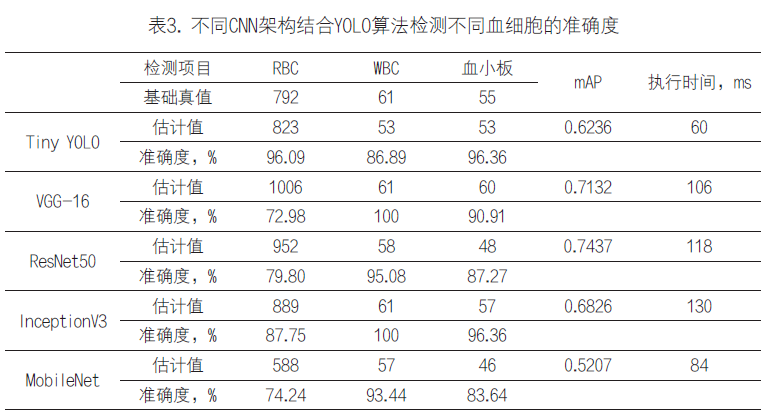
1. 利用其它CNN架构进行实验:受到GoogLeNet架构的启发,YOLO有一个内置的CNN分类架构。除了用YOLO自己的CNN训练血细胞检测模型,我们还用其它常用的CNN架构进行了实验。
我们用VGG-16、ResNet50、InceptionV3和MobileNet CNN架构替代YOLO算法的内置CNN。为了在后端用这些网络训练YOLO,我们将训练集分成两部分。前250幅带注释的图像用于训练,后50幅图像用于验证。对于所有网络,训练的损失曲线及验证的平均精度均值(mAP)如图6所示。
从图中可以看出,InceptionV3和ResNet50的误差最小。测试集中RBC、WBC和PLT计数的准确度如表3所示。从表中可以看出,使用Tiny YOLO架构对RBC和PLT进行计数的准确度最高,其中RBC计数的准确度达到96.09%,PLT计数的准确度达到96.36%。
另一方面,用VGG-16和InceptionV3进行WBC计数时准确度最高(100%)。因此,不同细胞的计数可以用不同的模型达到最高准确度。我们还计算了这些CNN架构的平均精度均值(mAP),各架构对每幅测试图像的执行时间如表3所示。从表中可以看出,ResNet50的mAP值最高。
YOLO血细胞识别和计数方法速度极快,即使进行更深的网络分析,也仅需不到一秒。我们在计算机(配置为8GB Intel Core i5 6500显卡,4GB Nvidia GTX1050 TiGPU)上计算了每幅测试图像所需的前向传播时间。通过计算平均值以获得最终执行时间来报告估计时间。

2. 用不同的数据集进行测试:为了确定训练模型是否具有数据库依赖性,我们还用另一个数据集的血涂片图像测试了模型。该数据集的图像具有较高的分辨率,因此图像被分成网格以创建子图像,并且在建议的图像渲染管线(pipeline)中单独处理每幅子图像。
然后将每幅子图像的检测和计数投射到原图像上。图7表示一幅被分成3×3网格的血涂片图像,也就是用建立的方法处理9幅子图像。从图中可以看出,输出图像正确识别了RBC、WBC和PLT,性能令人满意。

3. 结论:本文介绍了一种基于YOLO算法对血涂片图像中的血细胞进行自动识别和计数的机器学习方法。为了提高准确度,该方法利用KNN和IOU方法解决了同一目标的多重计数问题。用公开的数据集评估了YOLO血细胞识别和计数方法。
在测试数据集中,YOLO方法准确地识别了RBC、WBC和PLT。结果表明,即使数据集未对某些细胞进行标记,YOLO方法也能准确地计数。我们还在YOLO后端尝试了不同的神经网络模型,不同细胞的计数可以用不同的模型达到最高准确度。即使尝试了具有不同深度的不同模型,该方法在进行血涂片图像计数和标记时也非常快。
还用另外的血涂片图像数据集测试了YOLO方法,结果令人满意。鉴于该方法的准确度和检测性能,可以说它有可能简化手 动血细胞识别和计数过程。 |


