|
作者:刘勇1 王磊2 李东2 缪宇生2 单位:1.中国医科大学附属盛京医院检验科 2.东软集团股份有限公司临床医疗事业部
刘 勇 中国医科大学附属盛京医院检验科主任 研究员、教授、硕士生导师。社会兼职:中国医师协会检验医学分会常务委员、中国研究型医院学会检验医学专业委员会常务委员、中国老年医学会检验医学分会常务委员、中国医学装备协会检验医学分会第二届常务委员、中国医院协会临床微生物实验室管理专业委员会常务委员。中国医药教育协会感染病专业委员会理事、中国医院协会临床检验管理专业委员会委员、中国医师协会检验医师分会感染性疾病检验医学专家委员会副主任委员、中国微生物学会专业委员会细菌耐药性调查监测学组副主任委员、中华医学会微生物学与免疫学分会临床微生物学组委员、中国微生物学会临床微生物学专业委员会委员、华人抗菌药物敏感性试验委员会委员、中华预防医学会微生物态学分会微生物态诊断学组成员。主要研究方向:感染性疾病的流行病学调查和细菌耐药状况分析等。主持完成了多项省部级课题,发表论文数十篇,培养研究生十余名。 目前智能审核系统多是基于规则设计的,可以把一些可归纳及提取的审核逻辑做成规则,减少人工审核的工作量。规则设计的智能审核系统也存在一些问题,规则设计的合理性影响智能审核的准确率及通过率,规则中的隐藏误差不易被发现,人工设计的规则,智能审核通过率目前已达到瓶颈。 这时,需要新的技术来解决上面的问题。而人工智能的出现,为上面问题的解决提出了一种新的思路。本文中的智能审核系统,将采用监督学习方式的深度学习技术。 一 监督学习和深度学习的基本概念 监督学习(Supervised learning),是机器学习中的一种方法,可以由标记好的训练集中学到或建立一个模型,并依此模式推测新的实例。 深度学习(deep learning)是机器学习的分支,是一种以人工神经网络为架构,对数据进行特征学习的算法。深度学习运用了分层次抽象的思想,更高层次的概念从低层次的概念学习得到。这一分层结构常常使用贪心算法逐层构建而成,并从中选取有助于机器学习的更有效的特征[1]。 监督学习,需要标注数据集,对数据进行大量的人工标注。标注哪些数据能通过智能审核,哪些数据不能通过智能审核。人工智能来学习这些数据集,得到符合的权重参数及生成模型。 二 智能审核的总体架构
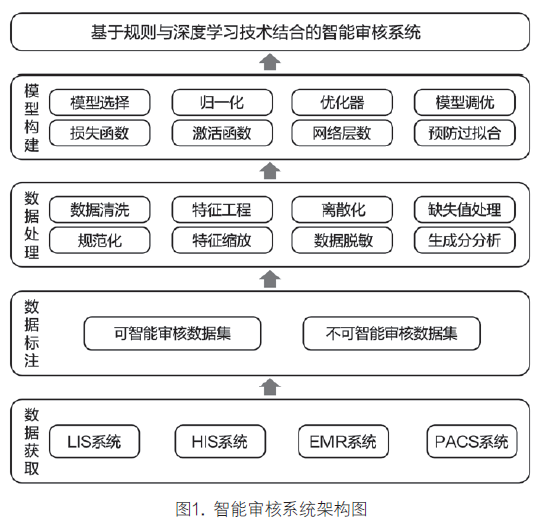
基于规则与深度学习技术结合的智能审核系统总体设计是:总体步骤为数据获取->数据标注->数据处理->模型构建四个步骤。1. 数据获取,数据获取来源于LIS系统与HIS系统,EMR等系统;2. 数据标注,通过设计的自动标注系统将数据集标注成可智能审核数据集及不可智能审核数据集;3. 数据处理,通过数据离散化,特征工程选择等处理数据集;4. 模型构建,选择对应的深度学习模型,设计模型层数,选择激活函数,模型调优等处理。完成最后智能审核系统的构建。 数据通过LIS系统,LIS系统与HIS,EMR系统的接口获取。 三 数据标注系统 获取到数据集之后,接下来要做数据标注,将数据集标注成可智能审核数据集及不可智能审核数据集。 人工智能的学习过程是一直在进行中的,如果人工标注的数据也一直在进行,则需耗费数据标注人员大量的时间。那么是否有一种方式,可以解决这个问题呢?一种基于规则的,自动标注系统,可以解决人工标注问题。一种基于规则的自动标注系统,包含基于规则的智能审核系统与标注系统两部分。基于规则的智能审核系统设计为包含以下规则: 1. 一致性分析规则[2]:将实际报告项目与医嘱申请项目进行比较,项目一致才可通过审核。 2. 患者用药限制规则:如采集时间减用药时间≤8小时,且患者使用的药品是阿斯匹林片,同时报告项目为血糖、尿素氮等,则报告单不能通过审核。 3. 采集时间要求规则:如血清钾(K)的结果时间减采集时间大于60分时,报告单不能通过审核。 4. 患者诊断限制规则:如诊断为肾功能衰竭的患者,有糖化血红蛋白检验结果的报告单不能通过审核。 5. 项目结果类型规则:如定量项目的结果需要满足为数值类型或者带有符号的数值类型。 6. 定量结果通过规则:定量项目的结果需要满足在设定的低值与高值范围内才能通过审核。 7. 两次结果要求通过规则:如设定某个项目30天内前后两次结果值相差在20%内才能通过审核[3]。 8. 项目关系要求通过规则:如血清总胆红素低于直接胆红素时不能通过审核[4]。 其标注系统设计为:基于规则的智能审核通过的数据,标注为审核通过数据。基于规则的智能审核未通过的数据,如未违反用药限制规则与诊断限制规则,且结果没有复查,直接通过人工审核的标本数据,这类数据可以由计算机程序标注为审核通过数据。其余的基于规则的审核未通过的数据,由计算机程序标注为审核未通过数据。 通过上面程序设定,实现了基于规则的自动标注系统,可以完成深度学习数据集的自动标注与建立。我们会得到两份数据集,可智能审核数据集与不可智能审核数据集。 四 数据清洗 在有了数据集之后,我们将进行深度学习模型的建立。深度学习模型的建立,一般经过以下几个步骤: 1. 数据清洗与预处理,模型的选择,模型的训练与调试。 2. 数据清洗与预处理中我们将采用离散化与归一化的方式。数据离散化是指将连续的数据进行分段,使其变为一段段离散化的区间。特征离散化后,模型会更稳定,比如对患者年龄离散化,1-14作为一个区间,处于这个区间的年龄对检验结果的影响是一致的。 3. 归一化技术,把需要处理的数据经过处理后,限制在需要的一定范围内,比如把数变为(0,1)之间的小数[5]。比如患者年龄,检测结果等经过数据归一化处理后,各指标处于同一数量级,适合进行综合对比评价。 对患者性别,患者科室进行离散化处理,对患者年龄,检测结果,30天内前次结果,参考值上限,参考值下限,危急值上限,危急值下限等进行归一化处理。 数据经过离散化,归一化处理之后,需要选取出数据中的关键特征,参考实验室目前报告审核流程及自动审核标准指南与相关论文,我们选择的特征如下:患者年龄,患者性别,患者科室,检测结果,30天内前次结果,参考范围,危急值范围,来生成深度学习的数据集。 五 模型构建与调优 接下来,我们需要生成深度学习模型,采用含有3个隐藏层全连接的深度神经网络(DNN)[6]。
深度模型中,需要加入激活函数。激活函数是在人工神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端。将非线性特性引入到我们的网络中,使网络更加强大,使它可以学习检验数据中更多的特征。我们智能审核模型选择ReLU(Rectified linear units线性修正单元)作为激活函数,它的梯度下降及反向传播更有效率,也能缓解过拟合问题。 模型如果学习了样本中的噪声,会产生过拟合现象。比如学习了很多不必要细节特征,如模型学习了过多的患者科室与检测结果的关系特征。在模型中,我们加入了Dropout技术,可以有效防止过拟合。Dropout(随机失活),每次训练时随机忽略一部分神经元。降低节点间的相互依赖性, 增加泛化能力,降低其结构风险[7]。 模型使用交叉熵作为损失函数。损失函数用于评估真实值与预测值之间的损失。损失越小,模型则越好。交叉熵损失函数的收敛速度比较快。比如评估标注的可智能审核数据与模型预测结果是否相符。 深度学习需要使用优化器来最小化损失函数。Adam优化器基于训练数据迭代地更新神经网络权重。Adam通过对梯度的一阶矩估计和二阶矩估计的计算,可以动态调整每个参数的学习率。Adam优化器有着收敛速度快,对内存占用小等优点[8]。 至此,基于规则与深度学习技术结合的智能审核系统设计完成。在模型训练中通过调整学习率,调整训练轮数,调整一次训练样本数等方式最小化损失,以训练得到最优的模型。 在模拟数据集中,验证生化报告,医嘱为血清离子(钾钠氯),结果项目为钾,钠,氯。总检验结果数183906 条,其中必须人工审核的检验结果数 5627 条,规则智能审核通过率:71.63%,深度学习模型智能审核通过率:87.14%,深度学习模型准确率:91.53%。 数据集每天都会有新的标本数据自动标注,模型也在不断学习。基于规则与深度学习技术结合的智能审核系统会验证更多数据情况,调整以适应更多类型报告单的智能审核。 参考文献略 |
Copyright © 2015-2023 杭州宇翼科技有限公司 丨 Discuz! X3.5 丨增值电信业务经营许可证:浙B2-20190572丨浙ICP备18026348号-1丨浙公网安备33010802009352号