|
隔壁神药丸子恢复更新了,咱也不能拉下啊。最近是蹭不上热度了,那就只能自己找点啥了。还好就在刚刚过去的10月Bioanalysis杂志诞生了3篇足以影响整个免疫原性检测圈的指导性文章(个人觉得哈,看到超激动的)。不能懒了,要不断学习! Stay Hungry,Stay Foolish. 首先第一篇是2019.10.16刊登的对免疫原性 “教父”(请允许我崇拜的用这个称呼,看着老爷子2008年那篇文章入的行),Shankar教授关于免疫原性现状的一篇访谈;第二篇是2019.10.22刊登的Charles River和Celerion两位专家前辈关于免疫原性中长期稳定性意义的思考;第三篇是2019.10.28刊登的EBF关于免疫原性试验(LBA)中关键试剂管理的白皮书。光看简介是不是就超激动,一浪高过一浪。别急,咱慢慢看,慢慢说。(后面附有全文链接)
一、教父的访谈 关于Shankar教授的这篇访谈实在是太崇拜了,不能不写几句。虽然访谈仅仅是他个人关于目前免疫原性评价中挑战的观点。但是相信圈内人都明白,这个意义是啥。Shankar教授提纲挈领的从免疫原性预测,免疫原性分析,临床中免疫原性三个方面谈了目前我们所面临的问题。 虽然最近几年技术不断进步,但是令人遗憾的是,免疫原性预测依旧还不算可靠。临床前即便使用转基因模型,免疫原性数据对临床仍然没有指导意义。但是对于内源性高度保守的蛋白临床前免疫原性风险可以有效的用以预估临床中副作用。在免疫原性分析方面法规中关于cut point及灵敏度的要求会让申办方和CRO做出过犹不及的事。免疫原性分析应该是要和临床结果进行紧密分析才对。在临床中免疫原性结果的解读不能仅仅停留在免疫原性发生率这个指标上,虽然医生和患者都会以这个指标来作为一个重要的判断标准。但是临床反应和发生率之间的关联才是更加重要的问题。为了推动数据的可靠性,进一步统一检测和数据解读的规范是重中之重。 免疫原性预测虽然还不够可靠,但是却能让候选药物筛选变得更为高效,我也愿意相信随着数据的不断积累,至少在某些靶点上,免疫原性预测能较为准确提前预估风险,像现在临床药理一样,通过in silico的模式为临床设计提供帮助。 法规方面随着2019版FDA免疫原性正式指导原则的生效,无论是cut point还是灵敏度确实都将过往产品的研发经验重置了(据我个人就FDA已批的生物药的免疫原性方法数据调研来看,就没几个能符合现在标准的)。正如Shankar教授所说,诚然这两个参数对于数据具有重要意义,但是随着法规要求的增高,目前大部分申报方和CRO在临床中都要更多的把精力放在建方法和改善方法参数上(至少以我们目前的状况而言的确是这样),或许我们应该更多的把精力放在临床免疫原性数据的解读和关联性上。但法规毕竟已经生效,大家怎么做,监管机构的尺度如何,或许还需要相当一段时间才能有数据的反馈。 对于免疫原性,由于其仍然缺乏统一的标准,真的需要能够尽量统一,期待早日ICH能有免疫原性的指导原则出现。当然这些还要靠如同Shankar教授的业内大佬们的共同推进了。
二、业内前辈们的思考 在免疫原性检测中,无论是CRO、申办方还是监管机构相信都被“长稳要不要做”,“该如何做”,“做的意义是啥”这个夺命三连问困扰过或者仍然被困扰中。好消息来了,随着这篇文献的发表,相信今后大家在回答这3个问题,包括作出决断的时候都能有个“靠山”了。 免疫原性检测具有半定量,阳性对照抗体无法代表体内真实情况并且个体间抗体产生的种类,比例,识别位点都不具有可比性的特点(免疫原性101的知识点了)。因此用阳性对照抗体来评价体内产生的抗体的稳定性就确实是有点玄学了。药物浓度分析时之所以我们可以这么干那是因为绝对定量,有标曲,标准品也可以代表体内的存在形式。那用标准品替代真实样品来评价稳定性是有意义且有必要的。毕竟谁都不希望因为药物不稳定导致数据没有意义。 抗药抗体检测时我们面临什么情况呢?首先,我们用的叫阳性对照(注意用词,是“对照”),只是为了作为试验体系的参照而已;其次体内的抗药抗体情况真的有点多,大概有多少可能呢,文献中给出了10^11的估算(1后面的零多到数不清)。我们首先是不清楚阳性对照的组成(多抗的情况下),其次也不知道每个个体中真实抗药抗体的组成。这就意味着,即使拿阳性对照去做长稳考察,最后也是啥也说明不了。本着科学出发的角度,这就没有科学依据,不能为了降低合规风险就不顾科学了。 两位前辈在文中给出了不同抗药抗体类型的长稳文献数据,几乎全部指向-20°以下可以长期保存2~18年(划重点,年数是基于不同的抗体类别,18年的数据是HIV抗体刷出来的)。也符合Shankar教授之前白皮书中的观点(大神再膜拜一下)。既然长稳不用做,做了也没意义,那是不是就可以放飞自我,啥稳定性都不做了呢。答案当然是:想得美。短期的及冻融稳定性由于会和具体的方法处理过程相关,并且这两条件相对也更为苛刻,一来文献没有支持,二来法规也有要求,三来确实有可能因为方法条件太剧烈导致过不了。 这篇文献的出现,相信可以为CRO,监管机构及申报方都提供一些有价值的信息,在考虑是否要做长稳的时候也不用那么纠结了。
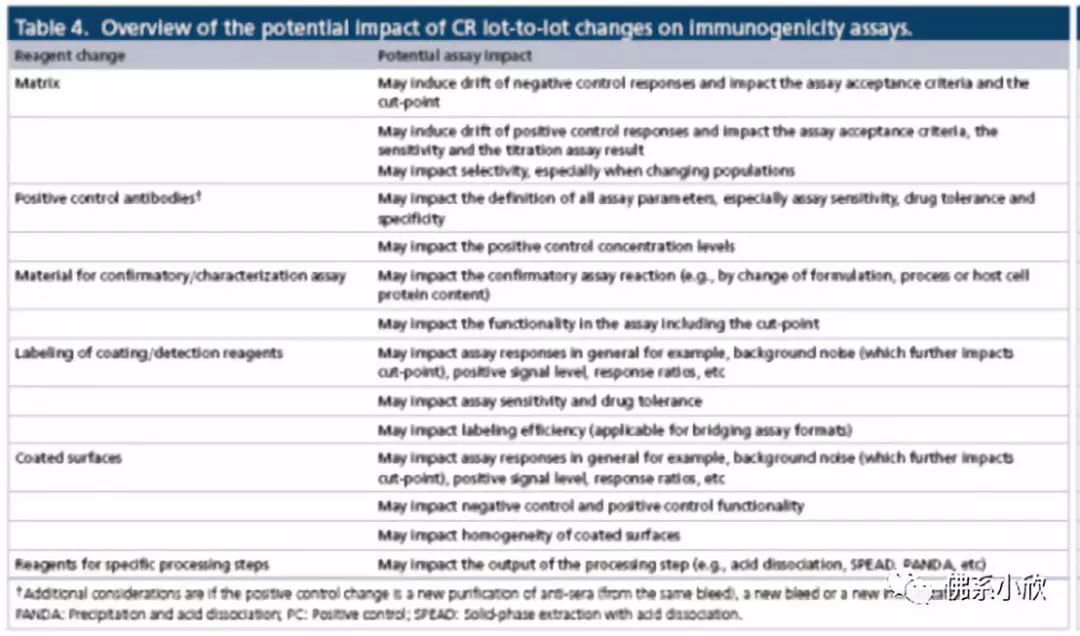
三、关键试剂管理的白皮书 对于配体结合试验而言,关键试剂管理极其重要,对于免疫原性检测中的配体结合试验那就更加重要了。半定量本质的加成使得控制变量更加困难。这个白皮书从关键试剂如何定义,关键试剂如何分类,关键试剂变化时产生的影响及对应影响应如何评价四大块进行了阐述(具体内容详见原文)。 抗药抗体检测中的关键试剂一般定义为一旦变化会对试验表现及参数产生直接影响的试剂。大家基本都能认同,阳性对照抗体,确证试验中外加的竞争试剂,标记试剂,空白基质是作为关键试剂需要进行严格管控和准备的。比较有效的管控方式是提前备货,在试验方法确定后备足货,让整个试验过程中这些试剂啥也别换。如果能做到这点,那读到这就可以了。 真实世界中哪有那么多岁月静好,多的是各种意外(最近手头项目各种问题,负面情绪有点重)。这些关键试剂总能出各种情况使得你不得不换个批号,或者换个来源。当出现更换后,如何把控就是本文的价值了。文中考虑了关键试剂更换可能产生的各种影响,比如空白基质批次的更换,会带来cut point的改变,标记试剂的重新标记甚至会带来试验条件的修改。具体见截图
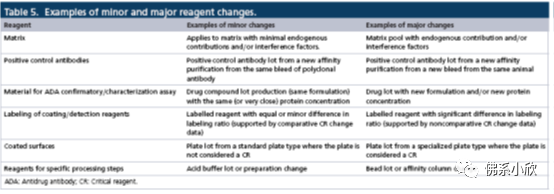
影响按范围大小分为微小及严重两类。举例基本涵盖了项目中可能出现的各种幺蛾子。具体见截图(别怪我懒,要是都写就成文献翻译了)
并且最为精彩的一点是以下两棵决策树。这就是实打实的操作指南啊。解决了目前项目中很多的疑惑。匹配更换前后的最好方式就是头对头同一批次比,但是意外总比顺利多,往往是各种糟糕的情况碰到一起,老的试剂批号用完了,新的还桥接不上(不要问我为什么知道,说多了都是泪)。见截图。
到这还不算完,白皮书中还对这些附加的桥接试验或者是更大范围的部分验证都提出了资料管理的建议。毕竟这部分在EMA或FDA的指导原则中都只提了要求,没说策略。 对于关键试剂的管控,在临床免疫原性中是肯定没法绕过去的坎。临床前周期短,样品少,只要数学好,不怕浪费,多备点试剂,一般不会需要担心这么多。临床就不一样了,I期爬坡慢,长的可能小半年才爬1个剂量,几个剂量爬下来,2年过去了;用药人群也不那么可控,肿瘤药中可能先各个瘤种都试一试;连供试品本身都会有变化,用药量太大,导致I期需要更换好几个批号。。。有了这个白皮书,后续出问题虽不指望能完全解决问题,至少可以有个参考。
到此,免疫原性中3个关键问题的思考阐述完毕。1,cut point和灵敏度真的要要求这么高么?2,长期稳定性考察可以不用进行,用文献支持。但是短期及冻融还是要做的。3,免疫原性方法中关键试剂需要严格管控及评估并记录在试验资料中。希望我的一点感悟能够给大家带来思考或者帮助。 参考文献 1,https://www.ncbi.nlm.nih.gov/pubmed/31617390 doi: 10.4155/bio-2019-0141. Current challenges in assessing immunogenicity.2,https://www.ncbi.nlm.nih.gov/pubmed/31637931 doi: 10.4155/bio-2019-0185. Assessing the long-term stability of anti-drug antibodies in method validation: what is the added value?3,https://www.ncbi.nlm.nih.gov/pubmed/31657235 doi: 10.4155/bio-2019-0248. |
Copyright © 2015-2023 杭州宇翼科技有限公司 丨 Discuz! X3.5 丨增值电信业务经营许可证:浙B2-20190572丨浙ICP备18026348号-1丨浙公网安备33010802009352号